
如何从链接原理的角度理解 fishhook 的设计思想?
最近在三刷《程序员的自我修养:链接、装载与库》,为了加深对于相关知识的理解,我又阅读了 fishhook 的源码。本文希望从程序的链接原理出发,详细介绍 fishhook 的设计原理,学习其中的设计思想。
概述
Fishhook 是 Facebook 开源的一款面向 iOS/macOS 平台的 符号动态重绑定 工具,允许开发者在运行时修改 Mach-O 中的符号(函数),从而实现 动态库 的函数 hook 能力。
Fishhook 提供了两个用于符号重绑定的接口,分别是:
1 | int rebind_symbols(struct rebinding rebindings[], size_t rebindings_nel); |
其中,rebind_symbols
可以在所有动态库范围内进行符号重绑定,而
rebind_symbols_image
则限制了动态库的范围,只能指定某一个动态库。
这里,我们先预设几个问题,后面会逐步进行解答:
- 问题一:fishhook 是在什么时候完成函数 hook 的?
- 问题二:fishhook 为什么只支持 hook 动态库函数?
为了能介绍清楚 fishhook 的实现原理,本文我将重点介绍程序的链接原理,包括:静态链接、动态链接。其中,涉及到的术语和概念主要是基于 ELF 可执行文件(或目标文件),在真正介绍 fishhook 的原理时,我会将 Mach-O 中的术语与 ELF 进行比较和映射,从而达到一个举一反三的效果。
可执行文件格式
在介绍链接原理之前,我们有必要先了解一下可执行文件(目标文件)的基本格式,不同的平台有着不同的格式,分别是:
- 对于 Windows 平台,其采用的是 PE(Portable Executable) 格式
- 对于 Linux 平台,其采用的是 ELF(Executable Linkable Format) 格式
- 对于 iOS/macOS 平台,其采用的是 Mach-O(Mach Object) 格式
尽管不同平台的可执行文件格式不同,但是它们的组织结构和规则是基本类似的。如下图所示,不同格式的可执行文件基本都包含如下几个部分:
- 文件头
- segment 表
- section 表
- section 数据
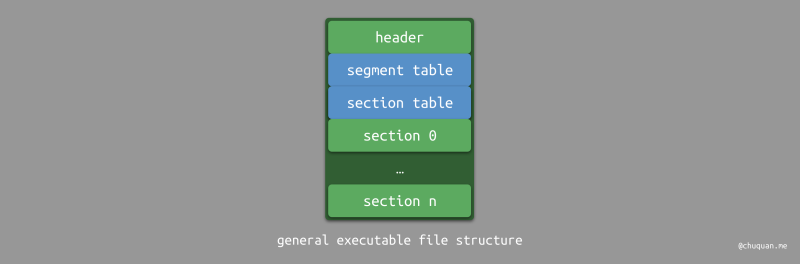
文件头用于描述可执行文件的元信息,包括:文件类型、系统版本、segment
表的位置和大小、section 表的位置和大小等等。Section
表本质上是一个索引表,其存储了每一个 section 的元信息,比如对应 section
在文件中的位置和大小。至于 section,它是可执行文件的基本组成单元,常见
section
有:.text、.data、.bss、.symtab、.strtab
等。
那么 segment 表的作用又是什么呢?
section 与 segment
事实上,两者的区别主要在于:section 用于描述可执行文件的静态存储布局,segment 用于描述可执行文件的装载内存布局。
我们知道可执行文件是以 section 为基本单元存储的,section
的类型非常多,如:.data、.text、.rodata
等。假如,我们的可执行文件中有两个 section,分别是 .init 和
.text,两者的大小分别是 3500B 和
4100B。假设系统的页面大小为 4KB,我们来分别看一下基于 section 装载和基于
segment 装载的内存占用情况。
下图右部所示为基于 section 装载的内存占用情况,其中
.init 单独占用一个页,且页没有全部使用;.text
会单独占用两个页,且第二页绝大多数内存空间没有使用,总共浪费内存 3 x 4KB
- 3500B - 4100B = 4688B。
下图左部所示为基于 segment 装载的内存占用情况,.text
占用了两个页,且与 .init 共享了一个页,总共浪费内存 2 x 4KB
- 3500B - 4100B = 592B。
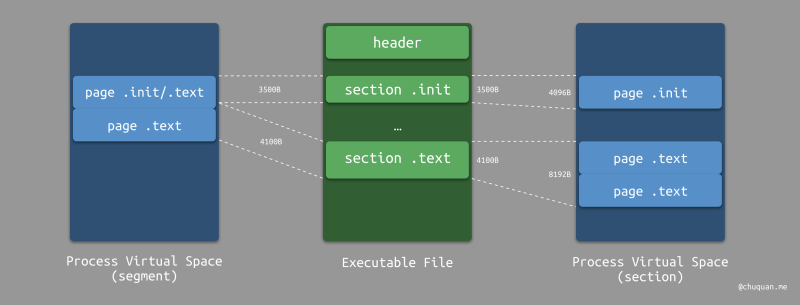
很显然,相比于基于 section 装载,基于 segment
装载对于内存占用的优化非常明显,内存碎片更少。在实际中,程序在装载时会将相同权限的
section 合并在一个 segment 中,比如:.init 和
.text 都合并成为可读可执行权限的
segment,作为代码段;可读可写的 section 合并在为一个
segment,作为数据段。
程序的链接原理
链接(Linking) 的本质是把多个目标文件相互拼接到一起,使得函数调用、变量访问等指令能够找到正确的内存地址。然而,这一切都是围绕着 符号(Symbol) 完成的。
那么到底什么是符号?举个例子,目标文件 B 调用了目标文件 A 中的函数
foo。对此,我们认为目标文件 A 定义了函数
foo,目标文件 B 引用了函数
foo。在链接过程中,我们将函数和变量统称为
符号(Symbol),函数名和和变量名统称为
符号名(Symbol Name)。因此,我们也可以认为目标文件 A
包含了函数 foo 的 符号定义(Symbol
Definition),目标文件 B 包含了函数 foo 的
符号引用(Symbol Reference)。
这时候问题来了,链接过程是如何基于符号完成对二进制指令中内存地址的修正呢?对此,我们可以先来了解一下静态链接。
静态链接
静态链接会在编译期将多个目标文件合并为一个可执行文件。因此,里面包含了所有的符号、重定位项、字符串等。
在编译过程中,编译器会为每一个变量或函数生成一个符号项,符号项包含的信息主要有:
- 符号名:即一个指向字符串表的索引,比如:字符串
foo在字符串表中的偏移量。 - 符号类型:类型有很多,比如:全局符号、局部符号、未定义符号等。
- 符号值:符号定义 的内存地址,用于修正二进制指令中的内存地址。这个地址修正的过程被称为 重定位。
此外,编译器还会为每个变量引用或函数引用生成一个重定位项。由于每一个重定位项记录了每一次对于符号的引用,因此,我们可以将其称为符号引用项。这样也就构成了符号定义和符号引用的一对多关系,毕竟,我们可以在不同的地方引用同一个变量或函数。
基于如下示意图,静态链接的整体工作原理大概可以分为以下三个步骤:
- 根据重定位项中的符号索引,去符号表找到对应的符号项,并获取到对应符号的符号值,即内存地址。
- 根据重定位项中的重定位地址,找到代码段中对应的字节地址,将其修正为步骤一获取到的内存地址。
- 遍历重定位表中的所有重定位项,重复步骤一和步骤二。
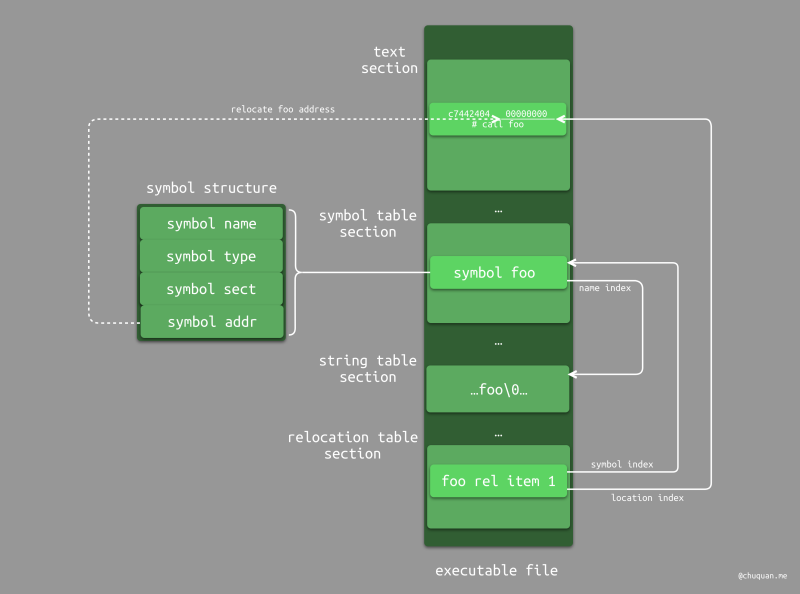
由于静态链接时,程序所依赖的所有目标文件都已经合并在了一个可执行文件中,因此几乎不存在符号项中的符号值(内存地址)不确定的情况,对此,静态链接器只需要基于重定位表进行重定位即可。这其实就是大家常说『静态链接的重点是重定位』的原因。
动态链接
动态链接的基本思想是 将程序按照模块拆分成各个独立的部分,在运行时将它们链接在一起形成一个完整的程序,而不是像静态链接一样在编译时把所有的模块都链接成一个独立的可执行文件。因此,动态链接可以有效解决静态链接存在的 内存空间浪费 和 程序更新困难 的问题。
那么对于动态链接,我们是否可以直接采用静态链接的做法呢?这种方案理论上可以,但却不是最优解,因为静态链接会修改代码段,我们很难让共享对象在被多次重定位之后也能继续安全稳定的运行。
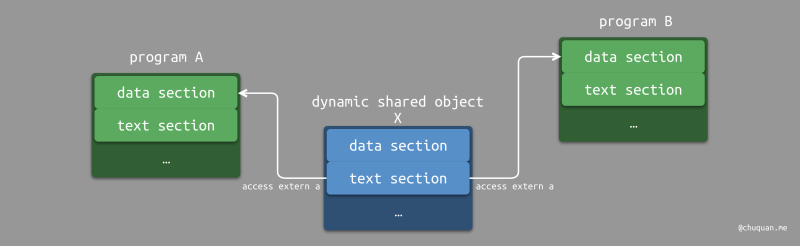
举一个例子,如下所示,一个动态共享对象 X
内部会引用外部的一个变量 a。当程序 A
与动态共享对象 X 完成重定位后,X
代码段中的某个指令的访存地址可能是一个值;当程序 B
与动态共享对象 X 完成重定位后,X
代码段中同位置的访存地址可能会被修改成另一个值。这时候,必然会出现其他程序无法正常执行的情况。
关于如何解决多进程之间的重定位冲突问题,我们可以引用下图所示的经典名言来描述动态链接的解决方案。当然,在具体的实现中,动态链接根据链接的时机,还可以分为 装载时链接(Load-Time Linking) 和 延迟链接(Lazy Linking)。两者的实现思路只有略微的差异,下面我们将分别进行介绍。

装载时链接
下图所示为装载时链接的工作原理示意图。对于共享对象而言,其代码段会被多个进程所共享,因此不能直接在代码段中进行重定位,修改内存地址。考虑到多进程共享对象时,共享对象会为每个进程拷贝一份数据段,支持修改。因此,一种称为 地址无关代码(PIC,Position-Independent Code) 的技术诞生了,其基本思想是:在编译时配置 PIC 编译选项,将指令部分中需要被修改的部分分离出来,跟数据部分放在一起。这样指令部分可以保持不变,而数据部分可以在每个进程中有一个独立的副本。
对于 PIC 技术,代码运行性能会比静态链接要差一点。因为指令在访问外部变量或外部函数时,必须先通过指针去数据段找到对应的位置,再从中取出真实的内存地址,很显然多了一次间接操作,损耗了性能。

在装载前,共享对象 X 的符号表中的外部符号
bar 的内存地址是未定义的。但是,程序 A
的符号表中的符号 bar 的内存地址是确定的(因为符号
bar 的符号定义位于程序 A
中)。因此,在装载时我们就可以决议出共享对象 X 的外部符号
bar 的地址。这个过程,我们称之为
装载时绑定(Load-Time Binding) 或
装载时符号绑定(Load-Time Symbol Binding)。
当外部符号 bar
的内存地址绑定完成后,我们就可以进行后续的重定位了。其步骤和静态链接的重定位类似,主要包括以下几步:
- 根据动态重定位项中的符号索引,去动态符号表中找到对应的符号项,并获取对应符号的符号值,即装载时绑定的内存地址。
- 根据动态重定位项中的重定位地址,找到 数据段 中对应的字节地址,将其修正为步骤一获取到的内存地址。
- 遍历动态重定位表中的所有重定位项,重复步骤一和步骤二。
在 PIC 技术中,编译器会在数据段中为每一个符号存储一个占位桩(stub),用于存储符号的真实内存地址。这些占位桩组成了一个表,我们称之为 全局偏移表(GOT,Global Offset Table)。
综上述可以看出,装载时链接包含了两个重要的步骤,分别是装载时绑定和重定位。虽然中间多了一步间接索引内存地址,损耗了一些性能,但是程序的灵活性和复用性提高了很多。
延迟链接
考虑到程序运行的局部性,实际上在进程生命周期中很多变量或函数并不会被调用。于是,诞生了延迟链接技术,可以支持进程只在第一次调用符号时才进行链接。
下图所示为延迟链接的工作原理示意图,本质上与装载时链接差不多,主要区别在于:装载时链接在数据段中使用了 GOT 存储符号地址,延迟链接则在数据段中使用了 过程链接表(PLT,Procedure Linkage Table) 存储符号地址。当 PLT 表项中符号的内存地址未决议时,PLT 表项中的占位桩(stub)存储的是一段代码的地址。当这段代码完成符号绑定和重定位后,会将符号的真实内存地址回填到占位桩中,覆盖默认的代码地址,从而实现仅在第一次调用符号时才进行链接。
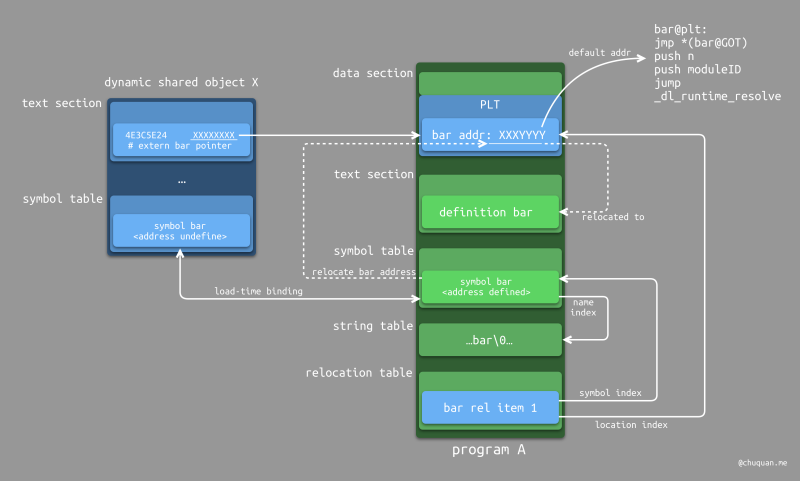
延迟链接的关键是如何实现在第一次调用符号时进行链接,这个过程包含了
延迟绑定(Lazy Binding) 和重定位。关于 PLT
的存储,很多目标文件会将其存储在命名为 got.plt 的 section
中,Mach-O 和 ELF 都是如此,这一点需要注意。
Fishhook 实现原理
核心思想
上述介绍了程序的链接原理,尤其是在理解了动态链接之后,如果你细想思考一下,很容易就能想到 fishhook 的设计思想。
下图展示了 fishhook 的设计思想,非常简单巧妙,核心思想就是 将目标符号(函数)对应的 GOT 表项或 PLT 表项中存储的符号值(内存地址),替换成 hook 函数的内存地址。通过这种方式,无论是装载时链接还是延迟链接,我们都可以实现对动态共享库函数的 hook。
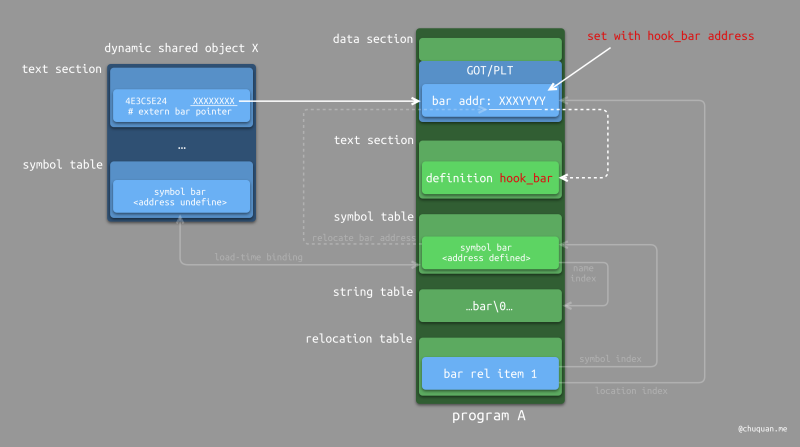
下面,我们来介绍一下 fishhook 实现细节中与 Mach-O 的相关概念。
Non-lazy Symbol Pointer & Lazy Symbol Pointer
如下所示为《Mach-O Programming Topics》中对两者的解释:
Non-lazy symbol references are resolved (bound to their definitions) by the dynamic linker when a module is loaded.A non-lazy symbol reference is essentially a symbol pointer—a pointer-sized piece of data. The compiler generates non-lazy symbol references for data symbols or function addresses.
Lazy symbol references are resolved by the dynamic linker the first time they are used (not at load time). Subsequent calls to the referenced symbol jump directly to the symbol’s definition.Lazy symbol references are made up of a symbol pointer and a symbol stub, a small amount of code that directly dereferences and jumps through the symbol pointer. The compiler generates lazy symbol references when it encounters a call to a function defined in another file.
Non-lazy Symbol Pointer 存储的是指向符号定义的指针,它与 GOT 中的表项定义非常类似。由 Non-lazy Symbol Pointer 组成的表,在 Mach-O 中我们称为 Non-lazy Symbol Pointer Table。
Lazy Symbol Pointer 包含一个指向符号定义的指针、一个占位桩以及一段代码(可用于延迟绑定和重定位),它与 PLT 中的表项定义非常类似。由 Lazy Symbol Pointer 组成的表,在 Mach-O 中我们称之为 Lazy Symbol Pointer Table。
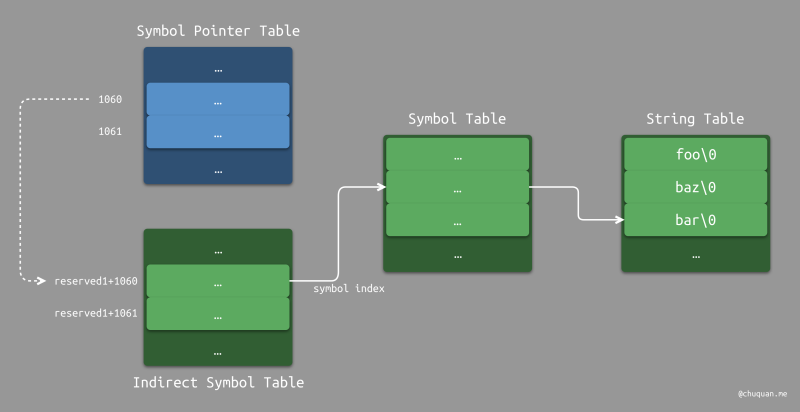
Indirect Symbol Table
上述的 Non-lazy Symbol Pointer 和 Lazy Symbol Pointer 并没有包含符号名相关的信息,然而在实际的符号查找、绑定的过程是需要用到的。因此,对于 Non-lazy Symbol Pointer Table 和 Lazy Symbol Pointer Table 各自有一个同步的间接符号表,可以用于配合完成链接工作。Fishhook 也是借助 Indirect Symbol Table 间接获取符号名,然后与目标符号进行判等比较,从而最终完成 hook 工作。
Indirect Symbol Table 与 Symbol Pointer Table 的表项是一一对应的,比如:Indirect Symbol Table 中第 1601 项存储的就是 Symbol Pointer Table 中第 1601 项的符号索引,如下图所示。
Symbol Pointer 目标符号地址替换
Fishhook 的核心是 完成 Symbol Pointer 的地址替换,无论是 Non-lazy Symbol Pointer 还是 Lazy Symbol Pointer。其实现的关键步骤主要包括以下几步:
- 查找数据段,即
SEG_DATA或SEG_DATA_CONST - 在数据段中查找
LAZY_SYMNBOL_POINTERS和NON_LAZY_SYMBOL_POINTERS类型的 section - 分别对
LAZY_SYMBOL_POINTERS和NON_LAZY_SYMBOL_POINTERSsection 进行 Symbol Pointer 目标符号地址替换
Symbol Pointer 目标符号地址替换的过程主要有以下几步:
- 根据
LAZY_SYMBOL_POINTERS或NON_LAZY_SYMBOL_POINTERSsection 获取其对应的 Indirect Symbol Table - 遍历 section,同步遍历 Indirect Symbol Table,获取对应的符号名
- 遍历过程中,判断符号名是否与目标符号名匹配。如果匹配,则将 Symbol Pointer 的符号地址替换成 hook 函数的地址;否则,继续遍历,直到结束。
这里涉及到了 fishhook 中的两个函数实现,分别是
rebind_symbols_for_image 函数和
perform_rebinding_with_section
函数,有兴趣的朋友可以自行阅读,本文就不粘贴代码了。
总结
至此,我们从链接原理的角度介绍了 fishhook 的设计思路。通过这种自顶向下的方法来分析,我们很快就可以联想到如何去实现一个针对 ELF 格式的 hook 工具。
最后,我们再来回顾一下本文开头预留的几个问题。
问题一:fishhook 是在什么时候完成函数 hook 的?fishhook 会在调用
rebind_symbols 或 rebind_symbols_image
方法时去遍历镜像,从而完成对目标符号的地址替换。
问题二:fishhook 为什么只支持 hook 动态库函数?动态库的 PIC 技术支持在数据段进行重定位,因此允许我们进行目标地址修改。而 fishhook 的整个机制就是建立在动态链接原理的基础上,因此仅支持 hook 动态库函数。
参考
- 《程序员的自我修养:装载、链接与库》
- OS X ABI Mach-O File Format Reference
- Mach-O Programming Topics
- fishhook
- BSD Library Functions Manual——dyld(3)
- dladdr(3) — Linux manual page